DeepSeek — The Model that broke the market

In today’s Finshots we see how a Chinese AI model wiped $1 trillion from the stock market.
The Story
Instead of writing a long winded essay to illustrate the answer, here’s a short concise version.
Until recently, the predominant belief was that you needed a lot of compute to build a foundational AI model — ChatGPT for instance. “Compute” may seem like a foreign term, but it’s really not. Compute means computers, only these are highly customized chips best suited to train an AI model.
Note: AI models much like humans need training and they’re trained using expensive computers.
And “compute” costs money. Tens of billions of dollars.
And since there are limited companies that build these chips (Nvidia being the forerunner with the best chips), there was a general expectation that supply constraints would prevent new players from creating foundation models (unless they also had tons of money and access to these chips).
And then, DeepSeek broke those expectations.
DeepSeek is a foundational AI model from China. And nobody expected it to be as good as it has been. Sure, China has always had the talent and the money to build something like this, but they didn’t have access to chips (or “compute”). The US government made sure the likes of Nvidia did not bulk export their latest chips to China or Chinese affiliated companies. So researchers in China only had access to limited compute (sourced before the export controls) or those in the wild. They couldn’t buy them at scale (or so everyone believes).
And yet, just last week, they released an AI model that competes with some of the best models from the US. And they did this at a fraction of the cost. They say that the whole training gig cost them $6 million. And even with the additional overheads (of people and their salaries), you are still looking at a tight tight ship. Meanwhile companies in the US have spent billions of dollars building the same models.
So as it stands, DeepSeek breaks a few big assumptions:
- Maybe you don’t need a lot of compute to build and train an AI model
- Maybe you don’t need a lot of money to build and train an AI model
- OpenAI, Microsoft, Google, Amazon have been grossly overpaying for building and training their models. Bad news!
- Fewer chip sales also affects Nvidia’s sales projections. Really bad news!
This explains why all the tech stocks have been crashing. Because this may set a new precedent for the future.
But that’s one version of the story.
So let’s go over this report once again, but this time with a little more nuance.
Alright! So China has figured out a way to build and train a foundational model with very little money. Great! But what’s preventing other more well funded players from doing the same thing? Why can’t they adopt the same approach, lower costs and rake in outsized profits as they keep refining their models even further?
Well, they could and they will likely do so. But DeepSeek is open source. This means anyone can access, configure, add inputs and deploy the model on their own terms. And that just opens the field now. Most tech companies in the US have been guarded in fully opening up their models. Even when they did, the models themselves weren’t all that great. But DeepSeek is all out there. For everyone. And it’s really really good. So now the US isn’t just competing with one model. They’re competing with an open source model where anybody can contribute.
So the big question is — Where is the competitive advantage for the likes of Microsoft, Google and OpenAI.
That’s something for investors to ponder.
But that’s not to say that everything about this story is squeaky clean. The researchers’ claims of using limited compute and resources to train a foundational model is just that — claims. It’s pretty fair to say that there are academics out there going over the research papers and trying to replicate the results. We will probably know for sure if the model is in fact as cheap as they claim pretty soon.
But even if we were to take the claims at face value, there is an added distinction here. The training cost of $6 million is likely the cost of renting the chips and not the cost of chips themselves. You can find this in the paper:
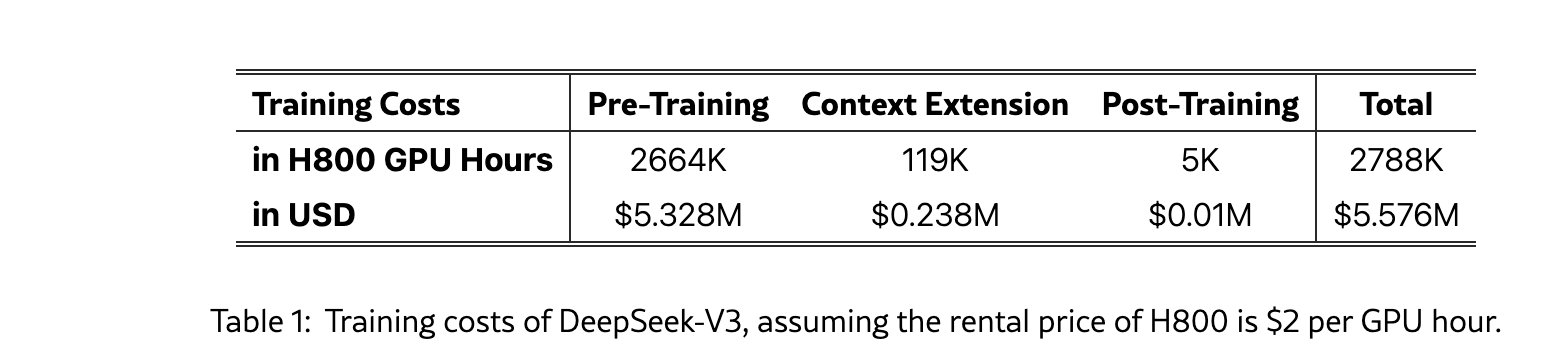
If you assume the cost of renting a chip is $2 per hour, then the total comes out to $5.57 million. This is not the actual cost of those chips. Also this excludes the cost of experimentation, prior research, salaries and other overheads. So no, it did not take just $6 million to build this. It likely took a lot more.
And finally let us also address another popular question that’s been doing the rounds of late — Why didn’t India do it? Why can’t we build our own DeepSeek?
Perhaps the best answer comes from a tweet by @bookwormengr. You can find the tweet here but to paraphrase this well put idea —
Protectionism! India is not a protected market. US companies can offer their AI services here and it will likely outperform any new Indian upstart — both in terms of service quality and price. China on the other hand is a protected market. US companies don’t have free rein and as a consequence, the consumers will have to adopt Chinese counterparts even if they are suboptimal at first. So there’s every incentive for a Chinese researcher to invest in building a foundational AI model because they have a ready market to tend to. India is different and as a consequence, researchers here have to work around the incentive problem to make their mark.
Can India do it? You tell us.
Until then…
Don’t forget to share this story on WhatsApp, LinkedIn and X.
📢Finshots has a new WhatsApp Channel! If you want the sharpest analysis of all financial news without the jargon, Finshots is the place to be! Click here to join.
75% of Indians are NOT covered by Life Insurance!
Don’t be a part of the herd — take the first step and lead the way.
A term life insurance plan offers a crucial safety net for your loved ones, ensuring they’ll be financially supported even in your absence.
Book a FREE call with Ditto to learn more about term life insurance and find the best plan for you and your family.